import numpy as np
WK1 = np.array([[1, 0, 1], [0, 1, 0], [1, 0, 1], [0, 1, 0]])
WV1 = np.array([[0, 1, 1], [1, 0, 0], [1, 0, 1], [0, 1, 0]])
WQ1 = np.array([[0, 0, 0], [1, 1, 0], [0, 0, 1], [1, 0, 0]])
WK2 = np.array([[0, 1, 1], [1, 0, 1], [1, 1, 0], [0, 1, 0]])
WV2 = np.array([[1, 0, 0], [0, 1, 1], [0, 0, 1], [1, 0, 0]])
WQ2 = np.array([[1, 0, 1], [0, 1, 0], [1, 0, 0], [0, 1, 1]])The Random Transformer
Understand how transformers work by demystifying all the math behind them
In this blog post, we’ll do an end-to-end example of the math within a transformer model. The goal is to get a good understanding of how the model works. To make this manageable, we’ll do lots of simplification. As we’ll be doing quite a bit of the math by hand, we’ll reduce the dimensions of the model. For example, rather than using embeddings of 512 values, we’ll use embeddings of 4 values. This will make the math easier to follow! We’ll use random vectors and matrices, but you can use your own values if you want to follow along.
As you’ll see, the math is not that complicated. The complexity comes from the number of steps and the number of parameters. I recommend you to read the The Illustrated Transformer blog before reading this blog post (or reading in parallel). It’s a great blog post that explains the transformer model in a very intuitive (and illustrative!) way and I don’t intend to explain what it’s already explained there. My goal is to explain the “how” of the transformer model, not the “what”. If you want to dive even deeper, check out the famous original paper: Attention is all you need.
Prerequisites
A basic understanding of linear algebra is required - we’ll mostly do simple matrix multiplications, so no need to be an expert. Apart from that, basic understanding of Machine Learning and Deep Learning will be useful.
What is covered here?
- An end-to-end example of the math within a transformer model during inference
- An explanation of attention mechanisms
- An explanation of residual connections and layer normalization
- Some code to scale it up!
Without further ado, let’s get started! Our goal will be to use the transformer model as a translation tool, so we’ll pass an input to the model expecting it to generate the translation. For example, we could pass “Hello World” in English and expect “Hola Mundo” in Spanish.
Let’s take a look at the diagram of the transformer beast (don’t be intimidatd by it, you’ll soon understand it!):
![]()
The original transformer model has two parts: encoder and decoder. The encoder focus is in “understanding” or “capturing the meaning” of the input text, while the decoder focus is in generating the output text. We’ll first focus on the encoder part.
Encoder
The whole goal of the encoder is to generate a rich embedding representation of the input text. This embedding will capture semantic information about the input, and will then be passed to the decoder to generate the output text. The encoder is composed of a stack of N layers. Before we jump into the layers, we need to see how to pass the words (or tokens) into the model.
Note
Embeddings are a somewhat overused term. We’ll first create an embedding that will be the input to the encoder. The encoder also outputs an embedding (also called hidden states sometimes). The decoder will also receive an embedding! 😅 The whole point of an embedding is to represent a token as a vector.
0. Tokenization
ML models can process numbers, not text. soo we need to turn our input text into numbers. That’s what tokenization does! This is the process of splitting the input text into tokens, each with an associated ID. For example, we could split the text “Hello World” into two tokens: “Hello” and “World”. We could also split it into characters: “H”, “e”, “l”, “l”, “o”, ” “,”W”, “o”, “r”, “l”, “d”. The choice of tokenization is up to us and depends on the data we’re working with.
Word-based tokenization (splitting the text into words) will require a very large vocabulary (all possible tokens). It will also represent words like “dog” and “dogs” or “run” and “running” as different tokens. Character-based vocabulary will require a smaller vocabulary, but will provide less meaning (in can be useful for languages such as Chinese where each character carries more information).
The field has moved towards subword tokenization. This is a middle ground between word-based and character-based tokenization. We’ll split the words into subwords. For example, we could split “tokenization” into “token” and “ization”. How do we decide how to split the words? This is part of training a tokenizer through a statistical process that tries to identify which subwords are the best to pick given a dataset. It’s a deterministic process (unlike training a ML model).
For this blog post, let’s go with word tokenization for simplicity. Our goal will be to translate “Hello World” from English to Spanish. Given an example “Hello World”, we’ll split into tokens: “Hello” and “World”. Each token has an associated ID defined in the model’s vocabulary. For example, “Hello” could be token 1 and “World” could be token 2.
1. Embedding the text
Although we could pass the token IDs to the model (e.g. 1 and 2), these numbers don’t carry any meaning. We need to turn them into vectors (list of numbers). This is what embedding does! The token embeddings map a token ID to a fixed-size vector with some semantic meaning of the tokens**. This brings some interesting properties: similar tokens will have a similar embedding (in other words, calculating the cosine similarity between two embeddings will give us a good idea of how similar the tokens are).
Note that the mapping from a token to an embedding is learned. Although we could use a pre-trained embedding such as word2vec or GloVe, transformers models learn these embeddings as part of their training. This is a big advantage as the model can learn the best representation of the tokens for the task at hand. For example, the model could learn that “dog” and “dogs” should have similar embeddings.
All embeddings in a single model have the same size. The original transformer used a size of 512, but let’s do 4 for our example so we can keep the maths manageable. I’ll assign some random values to each token (as mentioned, this mapping is usually learned by the model).
Hello -> [1,2,3,4]
World -> [2,3,4,5]
Note
After releasing this blog post, multiple persons raised questions about the embeddings above. I was a bit lazy and just wrote down some numbers that will make for some nice math below. In practice, these numbers would be learned by the model. I’ve updated the blog post to make this clearer. Thanks to everyone who raised this question!
We can estimate how similar these vectors are using cosine similarity, which would be too high for the vectors above. In practice, a vector would likely look something like [-0.071, 0.344, -0.12, 0.026, …, -0.008].
We can represent our input as a single matrix
\[ E = \begin{bmatrix} 1 & 2 & 3 & 4 \\ 2 & 3 & 4 & 5 \end{bmatrix} \]
Note
Although we could manage the two embeddings as separate vectors, it’s easier to manage them as a single matrix. This is because we’ll be doing matrix multiplications as we move forward!
2 Positional encoding
The individual embeddings in the matrix contain no information about the position of the words in the sentence”, so we need to feed some positional information. The way we do this is by adding a positional encoding to the embedding.
There are different choices on how to obtain these - we could use a learned embedding or a fixed vector. The original paper uses a fixed vector as they see almost no difference between the two approaches (see section 3.5 of the original paper). We’ll use a fixed vector as well. Sine and cosine functions have a wave-like pattern, and they repeat over time. By using these functions, each position in the sentence gets a unique yet consistent positional encoding. Given they repeat over time, it can help the model more easily learn patterns like proximity and distance between elements. These are the functions they use in the paper (section 3.5):
\[ PE(pos, 2i) = \sin\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right) \]
\[ PE(pos, 2i+1) = \cos\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right) \]
The idea is to interpolate between sine and cosine for each value in the embedding (even indices will use sine, odd indices will use cosine). Let’s calculate them for our example!
For “Hello”
- i = 0 (even): PE(0,0) = sin(0 / 10000^(0 / 4)) = sin(0) = 0
- i = 1 (odd): PE(0,1) = cos(0 / 10000^(2*1 / 4)) = cos(0) = 1
- i = 2 (even): PE(0,2) = sin(0 / 10000^(2*2 / 4)) = sin(0) = 0
- i = 3 (odd): PE(0,3) = cos(0 / 10000^(2*3 / 4)) = cos(0) = 1
For “World”
- i = 0 (even): PE(1,0) = sin(1 / 10000^(0 / 4)) = sin(1 / 10000^0) = sin(1) ≈ 0.84
- i = 1 (odd): PE(1,1) = cos(1 / 10000^(2*1 / 4)) = cos(1 / 10000^0.5) ≈ cos(0.01) ≈ 0.99
- i = 2 (even): PE(1,2) = sin(1 / 10000^(2*2 / 4)) = sin(1 / 10000^1) ≈ 0
- i = 3 (odd): PE(1,3) = cos(1 / 10000^(2*3 / 4)) = cos(1 / 10000^1.5) ≈ 1
So concluding
- “Hello” -> [0, 1, 0, 1]
- “World” -> [0.84, 0.99, 0, 1]
Note that these encodings have the same dimension as the original embedding.
Note
While we use sine and cosine as the original paper, there are other ways to do this. BERT, a very popular transformer, use trainable positional embeddings.
3. Add positional encoding and embedding
We now add the positional encoding to the embedding. This is done by adding the two vectors together.
“Hello” = [1,2,3,4] + [0, 1, 0, 1] = [1, 3, 3, 5] “World” = [2,3,4,5] + [0.84, 0.99, 0, 1] = [2.84, 3.99, 4, 6]
So our new matrix, which will be the input to the encoder, is:
\[ E = \begin{bmatrix} 1 & 3 & 3 & 5 \\ 2.84 & 3.99 & 4 & 6 \end{bmatrix} \]
If you look at the original paper’s image, what we just did is the bottom left part of the image (the embedding + positional encoding).
![]()
4. Self-attention
4.1 Matrices Definition
We’ll now introduce the concept of multi-head attention. Attention is a mechanism that allows the model to focus on certain parts of the input. Multi-head attention is a way to allow the model to jointly attend to information from different representation subspaces. This is done by using multiple attention heads. Each attention head will have its own K, V, and Q matrices.
Let’s use 2 attention heads for our example. We’ll use random values for these matrices. Each matrix will be a 4x3 matrix. With this, each matrix will transform the 4-dimensional embeddings into 3-dimensional keys, values, and queries. This reduces the dimensionality for attention mechanism, which helps in managing the computational complexity. Note that using a too small attention size will hurt the performance of the model. Let’s use the following values (just random values):
For the first head
\[ \begin{align*} WK1 &= \begin{bmatrix} 1 & 0 & 1 \\ 0 & 1 & 0 \\ 1 & 0 & 1 \\ 0 & 1 & 0 \end{bmatrix}, \quad WV1 &= \begin{bmatrix} 0 & 1 & 1 \\ 1 & 0 & 0 \\ 1 & 0 & 1 \\ 0 & 1 & 0 \end{bmatrix}, \quad WQ1 &= \begin{bmatrix} 0 & 0 & 0 \\ 1 & 1 & 0 \\ 0 & 0 & 1 \\ 1 & 1 & 0 \end{bmatrix} \end{align*} \]
For the second head
\[ \begin{align*} WK2 &= \begin{bmatrix} 0 & 1 & 1 \\ 1 & 0 & 1 \\ 1 & 0 & 1 \\ 0 & 1 & 0 \end{bmatrix}, \quad WV2 &= \begin{bmatrix} 1 & 0 & 0 \\ 0 & 1 & 1 \\ 0 & 0 & 1 \\ 1 & 0 & 0 \end{bmatrix}, \quad WQ2 &= \begin{bmatrix} 1 & 0 & 1 \\ 0 & 1 & 0 \\ 1 & 0 & 0 \\ 0 & 1 & 1 \end{bmatrix} \end{align*} \]
4.2 Keys, queries, and values calculation
We now need to multiply our input embeddings with the weight matrices to obtain the keys, queries, and values.
Key calculation
\[ \begin{align*} E \times WK1 &= \begin{bmatrix} 1 & 3 & 3 & 5 \\ 2.84 & 3.99 & 4 & 6 \end{bmatrix} \begin{bmatrix} 1 & 0 & 1 \\ 0 & 1 & 0 \\ 1 & 0 & 1 \\ 0 & 1 & 0 \end{bmatrix} \\ &= \begin{bmatrix} (1 \times 1) + (3 \times 0) + (3 \times 1) + (5 \times 0) & (1 \times 0) + (3 \times 1) + (3 \times 0) + (5 \times 1) & (1 \times 1) + (3 \times 0) + (3 \times 1) + (5 \times 0) \\ (2.84 \times 1) + (3.99 \times 0) + (4 \times 1) + (6 \times 0) & (2.84 \times 0) + (4 \times 1) + (4 \times 0) + (6 \times 1) & (2.84 \times 1) + (4 \times 0) + (4 \times 1) + (6 \times 0) \end{bmatrix} \\ &= \begin{bmatrix} 4 & 8 & 4 \\ 6.84 & 9.99 & 6.84 \end{bmatrix} \end{align*} \]
Ok, I actually do not want to do the math by hand for all of these - it gets a bit repetitive plus it breaks the site. So let’s cheat and use NumPy to do the calculations for us.
We first define the matrices
And let’s confirm that I didn’t make any mistakes in the calculations above.
embedding = np.array([[1, 3, 3, 5], [2.84, 3.99, 4, 6]])
K1 = embedding @ WK1
K1array([[4. , 8. , 4. ],
[6.84, 9.99, 6.84]])Phew! Let’s now get the values and queries
Value calculations
V1 = embedding @ WV1
V1array([[6. , 6. , 4. ],
[7.99, 8.84, 6.84]])Query calculations
Q1 = embedding @ WQ1
Q1array([[8. , 3. , 3. ],
[9.99, 3.99, 4. ]])Let’s skip the second head for now and focus on the first head final score. We’ll come back to the second head later.
4.3 Attention calculation
Calculating the attention score requires a couple of steps:
- Calculate the dot product of the query with each key
- Divide the result by the square root of the dimension of the key vector
- Apply a softmax function to obtain the attention weights
- Multiply each value vector by the attention weights
4.3.1 Dot product of query with each key
The score for “Hello” requires calculating the dot product of q1 with each key vector (k1 and k2)
\[ \begin{align*} q1 \cdot k1 &= \begin{bmatrix} 8 & 3 & 3 \end{bmatrix} \cdot \begin{bmatrix} 4 \\ 8 \\ 4 \end{bmatrix} \\ &= 8 \cdot 4 + 3 \cdot 8 + 3 \cdot 4 \\ &= 68 \end{align*} \]
In matrix world, that would be Q1 multiplied by the transpose of K1
\[\begin{align*} Q1 \times K1^\top &= \begin{bmatrix} 8 & 3 & 3 \\ 9.99 & 3.99 & 4 \end{bmatrix} \times \begin{bmatrix} 4 & 6.84 \\ 8 & 9.99 \\ 4 & 6.84 \end{bmatrix} \\ &= \begin{bmatrix} 8 \cdot 4 + 3 \cdot 8 + 3 \cdot 4 & 8 \cdot 6.84 + 3 \cdot 9.99 + 3 \cdot 6.84 \\ 9.99 \cdot 4 + 3.99 \cdot 8 + 4 \cdot 4 & 9.99 \cdot 6.84 + 3.99 \cdot 9.99 + 4 \cdot 6.84 \end{bmatrix} \\ &= \begin{bmatrix} 68 & 105.21 \\ 87.88 & 135.5517 \end{bmatrix} \end{align*}\]
I’m prone to do mistakes, so let’s confirm with Python once again
scores1 = Q1 @ K1.T
scores1array([[ 68. , 105.21 ],
[ 87.88 , 135.5517]])4.3.2 Divide by square root of dimension of key vector
We then divide the scores by the square root of the dimension (d) of the keys (3 in this case, but 64 in the original paper). Why? For large values of d, the dot product grows too large (we’re adding the multiplication of a bunch of numbers, after all, leading to high values). And large values are bad! We’ll discuss soon more about this.
scores1 = scores1 / np.sqrt(3)
scores1array([[39.2598183 , 60.74302182],
[50.73754166, 78.26081048]])4.3.3 Apply softmax function
We then softmax to normalize so they are all positive and add up to 1.
NoteWhat is softmax?
Softmax is a function that takes a vector of values and returns a vector of values between 0 and 1, where the sum of the values is 1. It’s a nice way of obtaining probabilities. It’s defined as follows:
\[ \text{softmax}(x_i) = \frac{e^{x_i}}{\sum_{j=1}^n e^{x_j}} \]
Don’t be intimidated by the formula - it’s actually quite simple. Let’s say we have the following vector:
\[ x = \begin{bmatrix} 1 & 2 & 3 \end{bmatrix} \]
The softmax of this vector would be:
\[ \text{softmax}(x) = \begin{bmatrix} \frac{e^1}{e^1 + e^2 + e^3} & \frac{e^2}{e^1 + e^2 + e^3} & \frac{e^3}{e^1 + e^2 + e^3} \end{bmatrix} = \begin{bmatrix} 0.09 & 0.24 & 0.67 \end{bmatrix} \]
As you can see, the values are all positive and add up to 1.
def softmax(x):
return np.exp(x) / np.sum(np.exp(x), axis=1, keepdims=True)
scores1 = softmax(scores1)
scores1array([[4.67695573e-10, 1.00000000e+00],
[1.11377182e-12, 1.00000000e+00]])4.3.4 Multiply value matrix by attention weights
We then multiply times the value matrix
attention1 = scores1 @ V1
attention1array([[7.99, 8.84, 6.84],
[7.99, 8.84, 6.84]])Let’s combine 4.3.1, 4.3.2, 4.3.3, and 4.3.4 into a single formula using matrices (this is from section 3.2.1 of the original paper):
\[ Attention(Q,K,V) = \text{softmax}\left(\frac{QK^\top}{\sqrt{d}}\right)V \]
Yes, that’s it! All the math we just did can easily be encapsulated in the attention formula above! Let’s now translate this to code!
def attention(x, WQ, WK, WV):
K = x @ WK
V = x @ WV
Q = x @ WQ
scores = Q @ K.T
scores = scores / np.sqrt(3)
scores = softmax(scores)
scores = scores @ V
return scoresattention(embedding, WQ1, WK1, WV1)array([[7.99, 8.84, 6.84],
[7.99, 8.84, 6.84]])We confirm we got same values as above. Let’s chear and use this to obtain the attention scores the second attention head:
attention2 = attention(embedding, WQ2, WK2, WV2)
attention2array([[8.84, 3.99, 7.99],
[8.84, 3.99, 7.99]])If you’re wondering how come the attention is the same for the two embeddings, it’s because the softmax is taking our scores to 0 and 1. See this:
softmax(((embedding @ WQ2) @ (embedding @ WK2).T) / np.sqrt(3))array([[1.10613872e-14, 1.00000000e+00],
[4.95934510e-20, 1.00000000e+00]])This is due to bad initialization of the matrices and small vector sizes. Large differences in the scores before applying softmax will just be amplified with softmax, leading to one value being close to 1 and others close to 0. In practice, our initial embedding matrices’ values were maybe too high, leading to high values for the keys, values, and queries, which just grew larger as we multiplied them.
Remember when we were dividing by the square root of the dimension of the keys? This is why we do that. If we don’t do that, the values of the dot product will be too large, leading to large values after the softmax. In this case, though, it seems it wasn’t enough given our small values! As a short-term hack, we can scale down the values by a larger amount than the square root of 3. Let’s redefine the attention function but scaling down by 30. This is not a good long-term solution, but it will help us get different values for the attention scores. We’ll get back to a better solution later.
def attention(x, WQ, WK, WV):
K = x @ WK
V = x @ WV
Q = x @ WQ
scores = Q @ K.T
scores = scores / 30 # we just changed this
scores = softmax(scores)
scores = scores @ V
return scoresattention1 = attention(embedding, WQ1, WK1, WV1)
attention1array([[7.54348784, 8.20276657, 6.20276657],
[7.65266185, 8.35857269, 6.35857269]])attention2 = attention(embedding, WQ2, WK2, WV2)
attention2array([[8.45589591, 3.85610456, 7.72085664],
[8.63740591, 3.91937741, 7.84804146]])4.3.5 Heads’ attention output
The next layer of the encoder will expect a single matrix, not two. The first step will be to concatenate the two heads’ outputs (section 3.2.2 of the original paper)
attentions = np.concatenate([attention1, attention2], axis=1)
attentionsarray([[7.54348784, 8.20276657, 6.20276657, 8.45589591, 3.85610456,
7.72085664],
[7.65266185, 8.35857269, 6.35857269, 8.63740591, 3.91937741,
7.84804146]])We finally multiply this concatenated matrix by a weight matrix to obtain the final output of the attention layer. This weight matrix is also learned! The dimension of the matrix ensures we go back to the same dimension as the embedding (4 in our case).
# Just some random values
W = np.array(
[
[0.79445237, 0.1081456, 0.27411536, 0.78394531],
[0.29081936, -0.36187258, -0.32312791, -0.48530339],
[-0.36702934, -0.76471963, -0.88058366, -1.73713022],
[-0.02305587, -0.64315981, -0.68306653, -1.25393866],
[0.29077448, -0.04121674, 0.01509932, 0.13149906],
[0.57451867, -0.08895355, 0.02190485, 0.24535932],
]
)
Z = attentions @ W
Zarray([[ 11.46394285, -13.18016471, -11.59340253, -17.04387829],
[ 11.62608573, -13.47454936, -11.87126395, -17.4926367 ]])The image from The Ilustrated Transformer encapsulates all of this in a single image 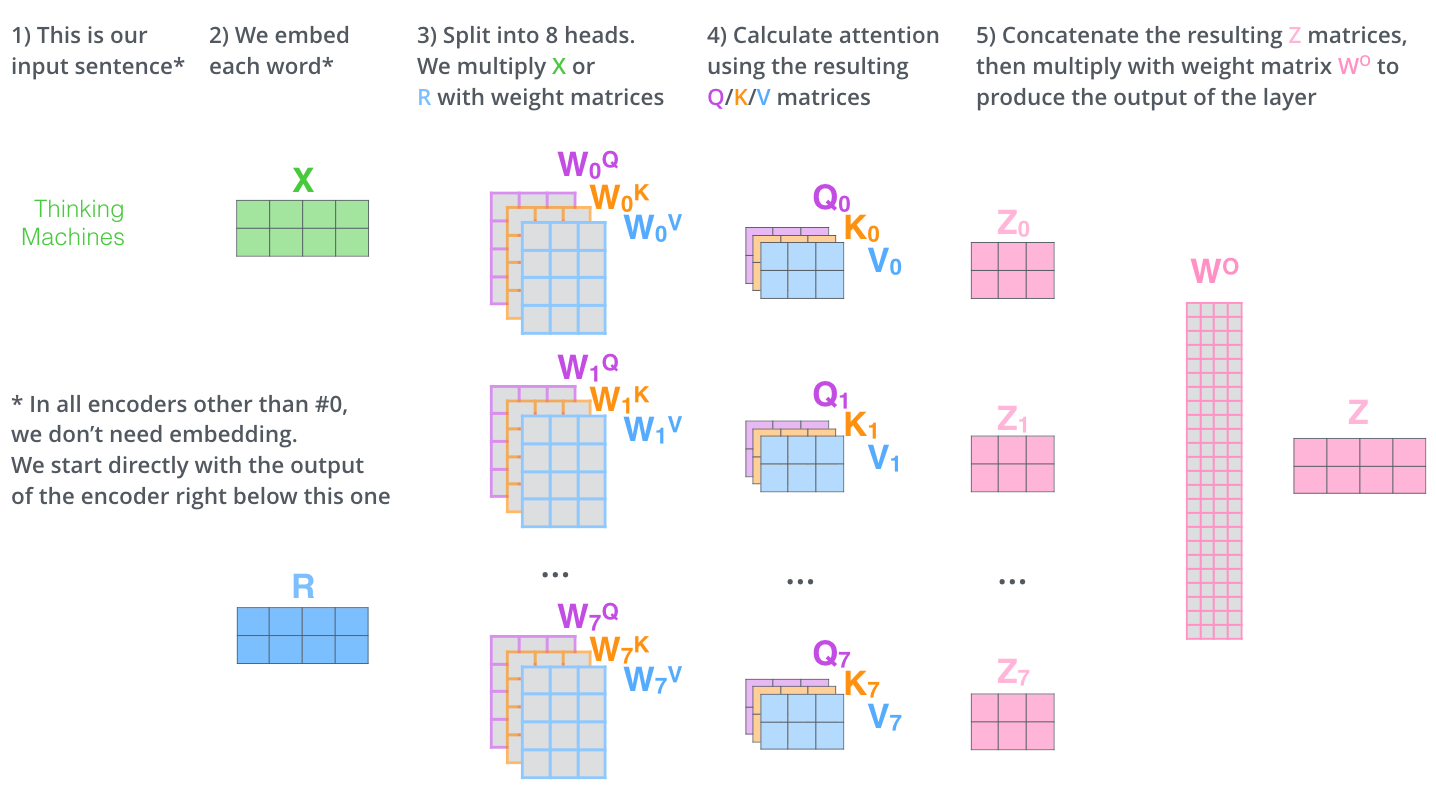
5. Feed-forward layer
5.1 Basic feed-forward layer
After the self-attention layer, the encoder has a feed-forward neural network (FFN). This is a simple network with two linear transformations and a ReLU activation in between. The Illustrated Transformer blog post does not dive into it, so let me briefly explain a bit more. The goal of the FFN is to process and transformer the representation produced by the attention mechanism. The flow is usually as follows (see section 3.3 of the original paper):
- First linear layer: this usually expands the dimensionality of the input. For example, if the input dimension is 512, the output dimension might be 2048. This is done to allow the model to learn more complex functions. In our simple of example with dimension of 4, we’ll expand to 8.
- ReLU activation: This is a non-linear activation function. It’s a simple function that returns 0 if the input is negative, and the input if it’s positive. This allows the model to learn non-linear functions. The math is as follows:
\[ \text{ReLU}(x) = \max(0, x) \]
- Second linear layer: This is the opposite of the first linear layer. It reduces the dimensionality back to the original dimension. In our example, we’ll reduce from 8 to 4.
We can represent all of this as follows
\[ \text{FFN}(x) = \text{ReLU}(xW_1 + b_1)W_2 + b_2 \]
Just as a reminder, the input for this layer is the Z we calculated in the self-attention above. Here are the values as a reminder
\[ Z = \begin{bmatrix} 11.46394281 & -13.18016469 & -11.59340253 & -17.04387833 \\ 11.62608569 & -13.47454934 & -11.87126395 & -17.49263674 \end{bmatrix} \]
Let’s now define some random values for the weight matrices and bias vectors. I’ll do it with code, but you can do it by hand if you feel patient!
W1 = np.random.randn(4, 8)
W2 = np.random.randn(8, 4)
b1 = np.random.randn(8)
b2 = np.random.randn(4)And now let’s write the forward pass function
def relu(x):
return np.maximum(0, x)
def feed_forward(Z, W1, b1, W2, b2):
return relu(Z.dot(W1) + b1).dot(W2) + b2output_encoder = feed_forward(Z, W1, b1, W2, b2)
output_encoderarray([[ -3.24115016, -9.7901049 , -29.42555675, -19.93135286],
[ -3.40199463, -9.87245924, -30.05715408, -20.05271018]])5.2 Encapsulating everything: The Random Encoder
Let’s now write some code to have the multi-head attention and the feed-forward, all together in the encoder block.
Note
The code optimizes for understanding and educational purposes, not for performance! Don’t judge too hard!
d_embedding = 4
d_key = d_value = d_query = 3
d_feed_forward = 8
n_attention_heads = 2
def attention(x, WQ, WK, WV):
K = x @ WK
V = x @ WV
Q = x @ WQ
scores = Q @ K.T
scores = scores / np.sqrt(d_key)
scores = softmax(scores)
scores = scores @ V
return scores
def multi_head_attention(x, WQs, WKs, WVs):
attentions = np.concatenate(
[attention(x, WQ, WK, WV) for WQ, WK, WV in zip(WQs, WKs, WVs)], axis=1
)
W = np.random.randn(n_attention_heads * d_value, d_embedding)
return attentions @ W
def feed_forward(Z, W1, b1, W2, b2):
return relu(Z.dot(W1) + b1).dot(W2) + b2
def encoder_block(x, WQs, WKs, WVs, W1, b1, W2, b2):
Z = multi_head_attention(x, WQs, WKs, WVs)
Z = feed_forward(Z, W1, b1, W2, b2)
return Z
def random_encoder_block(x):
WQs = [
np.random.randn(d_embedding, d_query) for _ in range(n_attention_heads)
]
WKs = [
np.random.randn(d_embedding, d_key) for _ in range(n_attention_heads)
]
WVs = [
np.random.randn(d_embedding, d_value) for _ in range(n_attention_heads)
]
W1 = np.random.randn(d_embedding, d_feed_forward)
b1 = np.random.randn(d_feed_forward)
W2 = np.random.randn(d_feed_forward, d_embedding)
b2 = np.random.randn(d_embedding)
return encoder_block(x, WQs, WKs, WVs, W1, b1, W2, b2)Recall that our input is the matrix E which has the positional encoding and the embedding.
embeddingarray([[1. , 3. , 3. , 5. ],
[2.84, 3.99, 4. , 6. ]])Let’s now pass this to our random_encoder_block function
random_encoder_block(embedding)array([[ -71.76537515, -131.43316885, 13.2938131 , -4.26831998],
[ -72.04253781, -131.84091347, 13.3385937 , -4.32872015]])Nice! This was just one encoder block. The original paper uses 6 encoders. The output of one encoder goes to the next, and so on:
def encoder(x, n=6):
for _ in range(n):
x = random_encoder_block(x)
return x
encoder(embedding)/tmp/ipykernel_11906/1045810361.py:2: RuntimeWarning: overflow encountered in exp
return np.exp(x)/np.sum(np.exp(x),axis=1, keepdims=True)
/tmp/ipykernel_11906/1045810361.py:2: RuntimeWarning: invalid value encountered in divide
return np.exp(x)/np.sum(np.exp(x),axis=1, keepdims=True)array([[nan, nan, nan, nan],
[nan, nan, nan, nan]])5.3 Residual and Layer Normalization
Uh oh! We’re getting NaNs! It seems our values are too high, and when being passed to the next encoder, they end up being too high and exploding! This issue of having values that are too high is a common issue when training models. For example, when doing the backpropagation (the technique through which the models learn), the gradients can become too large and end up exploding; this is called gradient explosion. Without any kind of normalization, small changes in the input of early layers end up being amplified in later layers. This is a common problem in deep neural networks. There are two common techniques to mitigate this problem: residual connections and layer normalization (section 3.1 of the paper, barely mentioned).
- Residual connections: Residual connections are simply adding the input of the layer to it output. For example, we add the initial embedding to the output of the attention. Residual connections mitigate the vanishing gradient problem. The intuition is that if the gradient is too small, we can just add the input to the output and the gradient will be larger. The math is very simple:
\[ \text{Residual}(x) = x + \text{Layer}(x) \]
That’s it! We’ll do this to the output of the attention and the output of the feed-forward layer.
- Layer normalization Layer normalization is a technique to normalize the inputs of a layer. It normalizes across the embedding dimension. The intuition is that we want to normalize the inputs of a layer so that they have a mean of 0 and a standard deviation of 1. This helps with the gradient flow. The math does not look so simple at a first glance.
\[ \text{LayerNorm}(x) = \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} \times \gamma + \beta \]
Let’s explain each parameter:
- \(\mu\) is the mean of the embedding
- \(\sigma\) is the standard deviation of the embedding
- \(\epsilon\) is a small number to avoid division by zero. In case the standard deviation is 0, this small epsilon saves the day!
- \(\gamma\) and \(\beta\) are learned parameters that control scaling and shifting steps.
Unlike batch normalization (no worries if you don’t know what it is), layer normalization normalizes across the embedding dimension - that means that each embedding will not be affected by other samples in the batch. The intuition is that we want to normalize the inputs of a layer so that they have a mean of 0 and a standard deviation of 1.
Why do we add the learnable parameters \(\gamma\) and \(\beta\)? The reason is that we don’t want to lose the representational power of the layer. If we just normalize the inputs, we might lose some information. By adding the learnable parameters, we can learn to scale and shift the normalized values.
Combining the equations, the equation for the whole encoder could look like this
\[ \text{Z}(x) = \text{LayerNorm}(x + \text{Attention}(x)) \]
\[ \text{FFN}(x) = \text{ReLU}(xW_1 + b_1)W_2 + b_2 \]
\[ \text{Encoder}(x) = \text{LayerNorm}(Z(x) + \text{FFN}(Z(x) + x)) \]
Let’s try with our example! Let’s go with E and Z values from before
\[ \begin{align*} \text{E} + \text{Attention(E)} &= \begin{bmatrix} 1.0 & 3.0 & 3.0 & 5.0 \\ 2.84 & 3.99 & 4.0 & 6.0 \end{bmatrix} + \begin{bmatrix} 11.46394281 & -13.18016469 & -11.59340253 & -17.04387833 \\ 11.62608569 & -13.47454934 & -11.87126395 & -17.49263674 \end{bmatrix} \\ &= \begin{bmatrix} 12.46394281 & -10.18016469 & -8.59340253 & -12.04387833 \\ 14.46608569 & -9.48454934 & -7.87126395 & -11.49263674 \end{bmatrix} \end{align*} \]
Let’s now calculate the layer normalization, we can divide it into three steps:
- Compute mean and variance for each embedding.
- Normalize by substracting the mean of its row and dividing by the square root of its row variance (plus a small number to avoid division by zero).
- Scale and shift by multiplying by gamma and adding beta.
5.3.1 Mean and variance
For the first embedding
\[ \begin{align*} \mu_1 &= \frac{12.46394281-10.18016469-8.59340253-12.04387833}{4} = -4.58837568 \\ \sigma^2 &= \frac{\sum (x_i - \mu)^2}{N} \\ &= \frac{(12.46394281 - (-4.588375685))^2 + \ldots + (-12.04387833 - (-4.588375685))^2}{4} \\ &= \frac{393.67443005013}{4} \\ &= 98.418607512533 \\ \sigma &= \sqrt{98.418607512533} \\ &= 9.9206152789297 \end{align*} \]
We can do the same for the second embedding. We’ll skip the calculations but you get the hang of it.
\[ \begin{align*} \mu_2 &= -3.59559109 \\ \sigma_2 &= 10.50653018 \end{align*} \]
Let’s confirm with Python
(embedding + Z).mean(axis=-1, keepdims=True)array([[-4.58837567],
[-3.59559107]])(embedding + Z).std(axis=-1, keepdims=True)array([[ 9.92061529],
[10.50653019]])Amazing! Let’s now normalize
5.3.2 Normalize
For normalization, for each value in the embedding, we subsctract the mean and divide by the standard deviation. Epsilon is a very small value, such as 0.00001. We’ll assume \(\gamma=1\) and \(\beta=0\), it simplifies things.
\[\begin{align*} \text{normalized}_1 &= \frac{12.46394281 - (-4.58837568)}{\sqrt{98.418607512533 + \epsilon}} \\ &= \frac{17.05231849}{9.9206152789297} \\ &= 1.718 \\ \text{normalized}_2 &= \frac{-10.18016469 - (-4.58837568)}{\sqrt{98.418607512533 + \epsilon}} \\ &= \frac{-5.59178901}{9.9206152789297} \\ &= -0.564 \\ \text{normalized}_3 &= \frac{-8.59340253 - (-4.58837568)}{\sqrt{98.418607512533 + \epsilon}} \\ &= \frac{-4.00502685}{9.9206152789297} \\ &= -0.404 \\ \text{normalized}_4 &= \frac{-12.04387833 - (-4.58837568)}{\sqrt{98.418607512533 + \epsilon}} \\ &= \frac{-7.45550265}{9.9206152789297} \\ &= -0.752 \end{align*}\]
We’ll skip the calculations by hand for the second embedding. Let’s confirm with code! Let’s re-define our encoder_block function with this change
def layer_norm(x, epsilon=1e-6):
mean = x.mean(axis=-1, keepdims=True)
std = x.std(axis=-1, keepdims=True)
return (x - mean) / (std + epsilon)
def encoder_block(x, WQs, WKs, WVs, W1, b1, W2, b2):
Z = multi_head_attention(x, WQs, WKs, WVs)
Z = layer_norm(Z + x)
output = feed_forward(Z, W1, b1, W2, b2)
return layer_norm(output + Z)layer_norm(Z + embedding)array([[ 1.71887693, -0.56365339, -0.40370747, -0.75151608],
[ 1.71909039, -0.56050453, -0.40695381, -0.75163205]])It works! Let’s retry to pass the embedding through the six encoders.
def encoder(x, n=6):
for _ in range(n):
x = random_encoder_block(x)
return x
encoder(embedding)array([[-0.335849 , -1.44504571, 1.21698183, 0.56391289],
[-0.33583947, -1.44504861, 1.21698606, 0.56390202]])Amazing! These values make sense and we don’t get NaNs! The idea of the stack of encoders is that they output a continuous representation, z, that captures the meaning of the input sequence. This representation is then passed to the decoder, which will genrate an output sequence of symbols, one element at a time.
Before diving into the decoder, here’s an image from Jay’s amazing blog post:
![]()
You should be able to explain each component at the left side! Quite impressive, right? Let’s now move to the decoder.
Decoder
Most of the thing we learned for encoders will be used in the decoder as well! The decoder has two self-attention layers, one for the encoder and one for the decoder. The decoder also has a feed-forward layer. Let’s go through each of these.
The decoder block receives two inputs: the output of the encoder and the generated output sequence. The output of the encoder is the representation of the input sequence. During inference, the generated output sequence starts with a special start-of-sequence token (SOS). During training, the target output sequence is the actual output sequence, shifted by one position. This will be clearer soon!
Given the embedding generated by the encoder and the SOS token, the decoder will then generate the next token of the sequence, e.g. “hola”. The decoder is autoregressive, that means that the decoder will take the previously generated tokens and again generate the second token.
- Iteration 1: Input is SOS, output is “hola”
- Iteration 2: Input is SOS + “hola”, output is “mundo”
- Iteration 3: Input is SOS + “hola” + “mundo”, output is EOS
Here, SOS is the start-of-sequence token and EOS is the end-of-sequence token. The decoder will stop when it generates the EOS token. It generates one token at a time. Note that all iterations use the embedding generated by the encoder.
Note
This autoregressive design makes decoder slow. The encoder is able to generate its embedding in a single forward pass while the decoder needs to do many forward passes. This is one of the reasons why architectures that only use the encoder (such as BERT or sentence similarity models) are much faster than decoder-only architectures (such as GPT-2 or BART).
Let’s dive into each step! Just as the encoder, the decoder is composed of a stack of decoder blocks. The decoder block is a bit more complex than the encoder block. The general structure is:
- (Masked) Self-attention layer
- Residual connection and layer normalization
- Encoder-decoder attention layer
- Residual connection and layer normalization
- Feed-forward layer
- Residual connection and layer normalization
We’re already familiar with all the math from 1, 2, 3, 5 and 6. See the right side of the image below, you’ll see that all these blocks you already know (the right part):
![]()
1. Embedding the text
The first text of the decoder is to embed the input tokens. The input token is SOS, so we’ll embed it. We’ll use the same embedding dimension as the encoder. Let’s assume the embedding vector for SOS is the following:
\[ E = \begin{bmatrix} 1 & 0 & 0 & 0 \end{bmatrix} \]
2. Positional encoding
We’ll now add the positional encoding to the embedding, just as we did for the encoder. Given it’s the same position as “Hello”, we’ll have same positional encoding as we did before:
- i = 0 (even): PE(0,0) = sin(0 / 10000^(0 / 4)) = sin(0) = 0
- i = 1 (odd): PE(0,1) = cos(0 / 10000^(2*1 / 4)) = cos(0) = 1
- i = 2 (even): PE(0,2) = sin(0 / 10000^(2*2 / 4)) = sin(0) = 0
- i = 3 (odd): PE(0,3) = cos(0 / 10000^(2*3 / 4)) = cos(0) = 1
3. Add positional encoding and embedding
Adding the positional encoding to the embedding is done by adding the two vectors together:
\[ E = \begin{bmatrix} 1 & 1 & 0 & 1 \end{bmatrix} \]
4. Self-attention
The first step within the decoder block is the self-attention mechanism. Luckily, we have some code for this and can just use it!
d_embedding = 4
n_attention_heads = 2
E = np.array([[1, 1, 0, 1]])
WQs = [np.random.randn(d_embedding, d_query) for _ in range(n_attention_heads)]
WKs = [np.random.randn(d_embedding, d_key) for _ in range(n_attention_heads)]
WVs = [np.random.randn(d_embedding, d_value) for _ in range(n_attention_heads)]
Z_self_attention = multi_head_attention(E, WQs, WKs, WVs)
Z_self_attentionarray([[ 2.19334924, 10.61851198, -4.50089666, -2.76366551]])
Note
Things are quite simple for inference. For training, things are a bit tricky. During training, we use unlabeled data: just a bunch of text data, frequentyl scraped from the web. While the encoder’s goal is to capture all information of the input, the decoder’s goal is to predict the most likely next token. This means that the decoder can only use the tokens that have been generated so far (it cannot cheat and see the next tokens).
Because of this, we use masked self-attention: we mask the tokens that have not been generated yet. This is done by setting the attention scores to -inf. This is done in the original paper (section 3.2.3.1). We’ll skip this for now, but it’s important to keep in mind that the decoder is a bit more complex during training.
5. Residual connection and layer normalization
Nothing magical here, we just add the input to the output of the self-attention and apply layer normalization. We’ll use the same code as before.
Z_self_attention = layer_norm(Z_self_attention + E)
Z_self_attentionarray([[ 0.17236212, 1.54684892, -1.0828824 , -0.63632864]])6. Encoder-decoder attention
This part is the new one! If you were wondering where do the encoder-generated embeddings come in, this is their moment to shine!
Let’s assume the output of the encoder is the following matrix
\[ \begin{bmatrix} -1.5 & 1.0 & -0.8 & 1.5 \\ 1.0 & -1.0 & -0.5 & 1.0 \end{bmatrix} \]
In the self-attention mechanism, we calculate the queries, keys, and values from the input embedding.
In the encoder-decoder attention, we calculate the queries from the previous decoder layer and the keys and values from the encoder output! All the math is the same as before; the only difference is what embedding to use for the queries. Let’s look at some code
def encoder_decoder_attention(encoder_output, attention_input, WQ, WK, WV):
# The next three lines are the key difference!
K = encoder_output @ WK # Note that now we pass the previous encoder output!
V = encoder_output @ WV # Note that now we pass the previous encoder output!
Q = attention_input @ WQ # Same as self-attention
# This stays the same
scores = Q @ K.T
scores = scores / np.sqrt(d_key)
scores = softmax(scores)
scores = scores @ V
return scores
def multi_head_encoder_decoder_attention(
encoder_output, attention_input, WQs, WKs, WVs
):
# Note that now we pass the previous encoder output!
attentions = np.concatenate(
[
encoder_decoder_attention(
encoder_output, attention_input, WQ, WK, WV
)
for WQ, WK, WV in zip(WQs, WKs, WVs)
],
axis=1,
)
W = np.random.randn(n_attention_heads * d_value, d_embedding)
return attentions @ WWQs = [np.random.randn(d_embedding, d_query) for _ in range(n_attention_heads)]
WKs = [np.random.randn(d_embedding, d_key) for _ in range(n_attention_heads)]
WVs = [np.random.randn(d_embedding, d_value) for _ in range(n_attention_heads)]
encoder_output = np.array([[-1.5, 1.0, -0.8, 1.5], [1.0, -1.0, -0.5, 1.0]])
Z_encoder_decoder = multi_head_encoder_decoder_attention(
encoder_output, Z_self_attention, WQs, WKs, WVs
)
Z_encoder_decoderarray([[ 1.57651431, 4.92489307, -0.08644448, -0.46776051]])This worked! You might be asking “why do we do this?”. The reason is that we want the decoder to focus on the relevant parts of the input text (e.g., “hello world”). The encoder-decoder attention allows each position in the decoder to attend over all positions in the input sequence. This is very helpful for tasks such as translation, where the decoder needs to focus on the relevant parts of the input sequence. The decoder will learn to focus on the relevant parts of the input sequence by learning to generate the correct output tokens. This is a very powerful mechanism!
7. Residual connection and layer normalization
Same as before!
Z_encoder_decoder = layer_norm(Z_encoder_decoder + Z_self_attention)
Z_encoder_decoderarray([[-0.44406723, 1.6552893 , -0.19984632, -1.01137575]])8. Feed-forward layer
Once again, same as before! I’ll also do the residual connection and layer normalization after it.
W1 = np.random.randn(4, 8)
W2 = np.random.randn(8, 4)
b1 = np.random.randn(8)
b2 = np.random.randn(4)
output = layer_norm(feed_forward(Z_encoder_decoder, W1, b1, W2, b2) + Z_encoder_decoder)
outputarray([[-0.97650182, 0.81470137, -2.79122044, -3.39192873]])9. Encapsulating everything: The Random Decoder
Let’s write the code for a single decoder block. The main change is that we now have an additional attention mechanism.
d_embedding = 4
d_key = d_value = d_query = 3
d_feed_forward = 8
n_attention_heads = 2
encoder_output = np.array([[-1.5, 1.0, -0.8, 1.5], [1.0, -1.0, -0.5, 1.0]])
def decoder_block(
x,
encoder_output,
WQs_self_attention, WKs_self_attention, WVs_self_attention,
WQs_ed_attention, WKs_ed_attention, WVs_ed_attention,
W1, b1, W2, b2,
):
# Same as before
Z = multi_head_attention(
x, WQs_self_attention, WKs_self_attention, WVs_self_attention
)
Z = layer_norm(Z + x)
# The next three lines are the key difference!
Z_encoder_decoder = multi_head_encoder_decoder_attention(
encoder_output, Z, WQs_ed_attention, WKs_ed_attention, WVs_ed_attention
)
Z_encoder_decoder = layer_norm(Z_encoder_decoder + Z)
# Same as before
output = feed_forward(Z_encoder_decoder, W1, b1, W2, b2)
return layer_norm(output + Z_encoder_decoder)
def random_decoder_block(x, encoder_output):
# Just a bunch of random initializations
WQs_self_attention = [
np.random.randn(d_embedding, d_query) for _ in range(n_attention_heads)
]
WKs_self_attention = [
np.random.randn(d_embedding, d_key) for _ in range(n_attention_heads)
]
WVs_self_attention = [
np.random.randn(d_embedding, d_value) for _ in range(n_attention_heads)
]
WQs_ed_attention = [
np.random.randn(d_embedding, d_query) for _ in range(n_attention_heads)
]
WKs_ed_attention = [
np.random.randn(d_embedding, d_key) for _ in range(n_attention_heads)
]
WVs_ed_attention = [
np.random.randn(d_embedding, d_value) for _ in range(n_attention_heads)
]
W1 = np.random.randn(d_embedding, d_feed_forward)
b1 = np.random.randn(d_feed_forward)
W2 = np.random.randn(d_feed_forward, d_embedding)
b2 = np.random.randn(d_embedding)
return decoder_block(
x, encoder_output,
WQs_self_attention, WKs_self_attention, WVs_self_attention,
WQs_ed_attention, WKs_ed_attention, WVs_ed_attention,
W1, b1, W2, b2,
)def decoder(x, decoder_embedding, n=6):
for _ in range(n):
x = random_decoder_block(x, decoder_embedding)
return x
decoder(E, encoder_output)array([[ 0.25919176, 1.49913566, -1.14331487, -0.61501256],
[ 0.25956188, 1.49896896, -1.14336934, -0.61516151]])Generating the output sequence
We have all the building blocks! Let’s now generate the output sequence.
- We have the encoder, which takes the input sequence and generates its rich representation. It’s composed of a stack of encoder blocks.
- We have the decoder, which takes the encoder output and generated tokens, and generates the output sequence. It’s composed of a stack of decoder blocks.
How do we go from the decoder’s output to a word? We need to add a final linear layer and a softmax layer on top of the decoder. The whole algorithm looks like this:
- Encoder Processing: The encoder receives the input sequence and generates a contextualized representation of the entire sequence, utilizing a stack of encoder blocks.
- Decoder Initiation: The decoding process begins with the embedding of the SOS (Start of Sequence) token, combined with the encoder’s output.
- Decoder Operation: The decoder uses the encoder’s output and the embeddings of all previously generated tokens to produce a new list of embeddings.
- Linear Layer for Logits A linear layer is applied to the latest output embedding from the decoder to generate logits, representing raw predictions for the next token.
- Softmax for Probabilities: These logits are then passed through a softmax layer, which converts them into a probability distribution over potential next tokens.
- Iterative Token Generation: This process is repeated, with each step involving the decoder generating the next token based on the cumulative embeddings of previously generated tokens and the initial encoder output.
- Sequence Completion: The generation continues through these steps until the EOS (End of Sequence) token is produced or a predefined maximum sequence length is reached.
This is mentioned in the section 3.4 of the paper.
1. Linear layer
The linear layer is a simple linear transformation. It takes the decoder’s output and transforms it into a vector of size vocab_size. This is the size of the vocabulary. For example, if we have a vocabulary of 10000 words, the linear layer will transform the decoder’s output into a vector of size 10000. This vector will contain the probability of each word being the next word in the sequence. For simplicity, let’s go with a vocabulary of 10 words and assume the first decoder output is a very simple vector: [1, 0, 1, 0]. We’ll use random weights and biases matrices of the size vocab_size x decoder_output_size.
def linear(x, W, b):
return np.dot(x, W) + b
x = linear([1, 0, 1, 0], np.random.randn(4, 10), np.random.randn(10))
xarray([ 0.06900542, -1.81351091, -1.3122958 , -0.33197364, 2.54767851,
-1.55188231, 0.82907169, 0.85910931, -0.32982856, -1.26792439])
Note
What do we use as input for the linear layer? The decoder will output one embedding for each token in the sequence. The input for the linear layer will be the last generated embedding. The last embedding encapsulates information to the entire sequence up to that point, so it contains all the information needed to generate the next token. This means that each output embedding from the decoder contains information about the entire sequence up to that point.
2. Softmax
These are called logits but they are not easily interpretable. We need to apply a softmax function to obtain the probabilities.
softmax(x)array([[0.01602618, 0.06261303, 0.38162024, 0.03087794, 0.0102383 ,
0.00446011, 0.01777314, 0.00068275, 0.46780959, 0.00789871]])This is giving us probabilities! Let’a assume the vocabulary is the following:
\[ \text{vocab} = \begin{bmatrix} \text{hello} & \text{mundo} & \text{world} & \text{how} & \text{?} & \text{EOS} & \text{SOS} & \text{a} & \text{hola} & \text{c} \end{bmatrix} \]
The above tells us that the probabilities are
- hello: 0.01602618
- mundo: 0.06261303
- world: 0.38162024
- how: 0.03087794
- ?: 0.0102383
- EOS: 0.00446011
- SOS: 0.01777314
- a: 0.00068275
- hola: 0.46780959
- c: 0.00789871
From these, the most likely next token is “hola”. Picking always the most likely token is called greedy decoding. This is not always the best approach, as it might lead to suboptimal results, but we won’t dive into generation techniques at the moment. If you want to learn more about it, check out this amazing blog post.
3. The Random Encoder-Decoder Transformer
Let’s write the whole code for this! Let’s define a dictionary that maps the words to their initial embeddings. Note that this is also learned during training, but we’ll use random values for now.
vocabulary = [
"hello",
"mundo",
"world",
"how",
"?",
"EOS",
"SOS",
"a",
"hola",
"c",
]
embedding_reps = np.random.randn(10, 4)
vocabulary_embeddings = {
word: embedding_reps[i] for i, word in enumerate(vocabulary)
}
vocabulary_embeddings{'hello': array([-0.32106406, 2.09332588, -0.77994069, 0.92639774]),
'mundo': array([-0.59563791, -0.63389256, 1.70663692, -0.99495115]),
'world': array([ 1.35581862, -0.0323546 , 2.76696887, 0.83069982]),
'how': array([-0.52975474, 0.94439644, 0.80073818, -1.50135518]),
'?': array([-0.88116833, 0.13995055, 2.01827674, -0.52554391]),
'EOS': array([1.12207024, 1.40905796, 1.22231714, 0.02267638]),
'SOS': array([-0.60624082, -0.67560165, 0.77152125, 0.63472247]),
'a': array([ 1.67622229, -0.20319309, -0.18324905, -0.24258774]),
'hola': array([ 1.07809402, -0.83846408, -0.33448976, 0.28995976]),
'c': array([ 0.65643157, 0.24935726, -0.80839751, -1.87156293])}And now let’s write our random generate method that generates tokens autorergressively.
def generate(input_sequence, max_iters=3):
# We first encode the inputs into embeddings
# This skips the positional encoding step for simplicity
embedded_inputs = [
vocabulary_embeddings[token] for token in input_sequence
]
print("Embedding representation (encoder input)", embedded_inputs)
# We then generate an embedding representation
encoder_output = encoder(embedded_inputs)
print("Embedding generated by encoder (encoder output)", encoder_output)
# We initialize the decoder output with the embedding of the start token
sequence_embeddings = [vocabulary_embeddings["SOS"]]
output = "SOS"
# Random matrices for the linear layer
W_linear = np.random.randn(d_embedding, len(vocabulary))
b_linear = np.random.randn(len(vocabulary))
# We limit number of decoding steps to avoid too long sequences without EOS
for i in range(max_iters):
# Decoder step
decoder_output = decoder(sequence_embeddings, encoder_output)
# Only use the last output for prediction
logits = linear(decoder_output[-1], W_linear, b_linear)
# We wrap logits in a list as our softmax expects batches/2D array
probs = softmax([logits])
# We get the most likely next token
next_token = vocabulary[np.argmax(probs)]
sequence_embeddings.append(vocabulary_embeddings[next_token])
output += " " + next_token
print(
"Iteration", i,
"next token", next_token,
"with probability of", np.max(probs),
)
# If the next token is the end token, we return the sequence
if next_token == "EOS":
return output
return output, sequence_embeddingsLet’s run this now!
generate(["hello", "world"])Embedding representation (encoder input) [array([-0.32106406, 2.09332588, -0.77994069, 0.92639774]), array([ 1.35581862, -0.0323546 , 2.76696887, 0.83069982])]
Embedding generated by encoder (encoder output) [[ 1.14747807 -1.5941759 0.36847675 0.07822107]
[ 1.14747705 -1.59417696 0.36847441 0.07822551]]
Iteration 0 next token hola with probability of 0.4327111653266739
Iteration 1 next token mundo with probability of 0.4411354383451089
Iteration 2 next token world with probability of 0.4746898792307499('SOS hola mundo world',
[array([-0.60624082, -0.67560165, 0.77152125, 0.63472247]),
array([ 1.07809402, -0.83846408, -0.33448976, 0.28995976]),
array([-0.59563791, -0.63389256, 1.70663692, -0.99495115]),
array([ 1.35581862, -0.0323546 , 2.76696887, 0.83069982])])Ok, so we got the tokens “how”, “a”, and “c”. This is not a good translation, but it’s expected! We only used random weights!
I suggest you to look again in detail at the whole encoder-decoder architecture from the original paper:
![]()
Conclusions
I hope that was fun and informational! We covered a lot of ground. Wait…was that it? And the answer is, mostly, yes! New transformer architectures add lots of tricks, but the core of the transformer is what we just covered. Depending on what task you want to solve, you can also only the encoder or the decoder. For example, for understanding-heavy tasks such as classification, you can use the encoder stack with a linear layer on top. For generation-heavy tasks such as translation, you can use the encoder and decoder stacks. And finally, for free generation, as in ChatGPT or Mistral, you can use only the decoder stack.
Of course, we also did lots of simplifications. Let’s briefly check which were the numbers in the original transformer paper:
- Embedding dimension: 512 (4 in our example)
- Number of encoders: 6 (6 in our example)
- Number of decoders: 6 (6 in our example)
- Feed-forward dimension: 2048 (8 in our example)
- Number of attention heads: 8 (2 in our example)
- Attention dimension: 64 (3 in our example)
We just covered lots of topics, but it’s quite interesting we can achieve impressive results by scaling up this math and doing smart training. We didn’t cover training in this blog post as the goal was to understand the math when using an existing model, but I hope this provided strong foundations for jumping into the training part. I hope you enjoyed this blog post!
You can also find a more formal document with the math in this PDF (recommended by HackerNews folks).
Exercises
Here are some exercises to practice your understanding of the transformer.
- What is the purpose of the positional encoding?
- How does self-attention and encoder-decoder attention differ?
- What would happen if our attention dimension was too small? What about if it was too large?
- Briefly describe the structure of a feed-forward layer.
- Why is the decoder slower than the encoder?
- What is the purpose of the residual connections and layer normalization?
- How do we go from the decoder output to probabilities?
- Why is picking the most likely next token every single time problematic?